FAQs
If you encounter errors in dayu system, please follow these steps to troubleshoot and use FAQs to solve:
✅ Check Dayu Pods: Use kubectl get pods -n <your-dayu-namespace> to check dayu pods status.
Use kubectl logs <pod-name> -n <your-dayu-namespace> and kubectl describes pod <pod-name> -n <your-dayu-namespace> to check log information in abnormal pods.
✅ Check Dayu Core Resources: Use kubectl get svc -n <your-dayu-namespace> and kubectl get deployment -n <your-dayu-namespace> to check services and deployments if pods are in unknown status.
✅ Check Node Connections: Use kubectl get nodes to check node status in the distributed cloud-edge system ('Ready' or 'Not Ready').
✅ Check Sedna: Check Sedna gm and lc logs with kubectl get pods -n sedna -owide and kubectl logs <sedna-pod-name> -n sedna.
✅ Check EdgeMesh: Check EdgeMesh agent logs with kubectl get pods -n kubeedge -owide and kubectl logs <edgemesh-pod-name> -n kubeedge if communication between nodes is blocked.
✅ Check Cloudcore: Use systemctl status cloudcore or journalctl -u cloudcore -xe on the cloud server to check cloudcore is running without errors.
✅ Check Edgecore: Use systemctl status edgecore or journalctl -u edgecore -xe on the edge device to check edgecore is running without errors.
✅ Check Kubelet Use systemctl status kubelet or journalctl -u kubelet -xe on the cloud server to check k8s administrator service is running without errors.
✅ Check Docker: If none of the kubectl commands or other k8s commands works, check docker container status with docker ps -a and check docker logs with systemctl status docker or journalctl -u docker -xe.
Question 1: kube-proxy report iptables problems
E0627 09:28:54.054930 1 proxier.go:1598] Failed to execute iptables-restore: exit status 1 (iptables-restore: line 86 failed ) I0627 09:28:54.054962 1 proxier.go:879] Sync failed; retrying in 30s
Solution: Clear iptables directly.
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
Question 2: calico and coredns are always in initializing state
The follwoing message will occur when using kubectl describe <podname> which is roughly related to network and sandbox issues.
Failed to create pod sandbox: rpc error: code = Unknown desc = [failed to set up sandbox container "7f5b66ebecdfc2c206027a2afcb9d1a58ec5db1a6a10a91d4d60c0079236e401" network for pod "calico-kube-controllers-577f77cb5c-99t8z": networkPlugin cni failed to set up pod "calico-kube-controllers-577f77cb5c-99t8z_kube-system" network: error getting ClusterInformation: Get "https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default": dial tcp 10.96.0. 1:443: i/o timeout, failed to clean up sandbox container "7f5b66ebecdfc2c206027a2afcb9d1a58ec5db1a6a10a91d4d60c0079236e401" network for pod "calico-kube-controllers-577f77cb5c-99t8z": networkPlugin cni failed to teardown pod "calico-kube-controllers-577f77cb5c-99t8z_kube-system" network: error getting ClusterInformation: Get "https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default": dial tcp 10.96.0. 1:443: i/o timeout]
Reason: Such a problem occurs when a k8s cluster is initialized more than once and the network configuration of k8s was not deleted previously.
Solution:
# delete k8s network configuration
rm -rf /etc/cni/net.d/
# reinitialize k8s with the instruction
Question 3: metrics-server keeps unsuccessful state
Reason: Master node does not add taint.
Solution:
# add taint on master node
kubectl taint nodes --all node-role.kubernetes.io/master node-role.kubernetes.io/master
Question 4: 10002 already in use
Error message 'xxx already in use' occurs when using journalctl -u cloudcore.service -xe.
Reason: The previous processes were not cleaned up.
Solution: Find the process occupying the port and directly kill it.
lsof -i:xxxx
kill xxxxx
Question 5: edgecore file exists
When attempting to create a symbolic link in installing edgecore, the target path already exists and cannot be created.
execute keadm command failed: failed to exec 'bash -c sudo ln /etc/kubeedge/edgecore.service /etc/systemd/system/edgecore.service && sudo systemctl daemon-reload && sudo systemctl enable edgecore && sudo systemctl start edgecore', err: ln: failed to create hard link '/etc/systemd/system/edgecore.service': File exists, err: exit status 1
Reason: edgecore.service already exists in the /etc/systemd/system/ directory
if edgecore is installed more than once.
Solution: Just delete it.
sudo rm /etc/systemd/system/edgecore.service
Question 6: TLSStreamPrivateKeyFile not exist
TLSStreamPrivateKeyFile: Invalid value: "/etc/kubeedge/certs/stream.key": TLSStreamPrivateKeyFile not exist
12月 14 23:02:23 cloud.kubeedge cloudcore[196229]: TLSStreamCertFile: Invalid value: "/etc/kubeedge/certs/stream.crt": TLSStreamCertFile not exist
12月 14 23:02:23 cloud.kubeedge cloudcore[196229]: TLSStreamCAFile: Invalid value: "/etc/kubeedge/ca/streamCA.crt": TLSStreamCAFile not exist
12月 14 23:02:23 cloud.kubeedge cloudcore[196229]: ]
Solution: Check whether directory /etc/kubeedge has file certgen.sh and run bash certgen.sh stream.
Question 7: EdgeMesh has successful edge-edge but failed cloud-edge connection
Troubleshooting:
First, based on the location model, ensure whether the edgemesh-agent container exists on the visited node and whether it is operating normally.
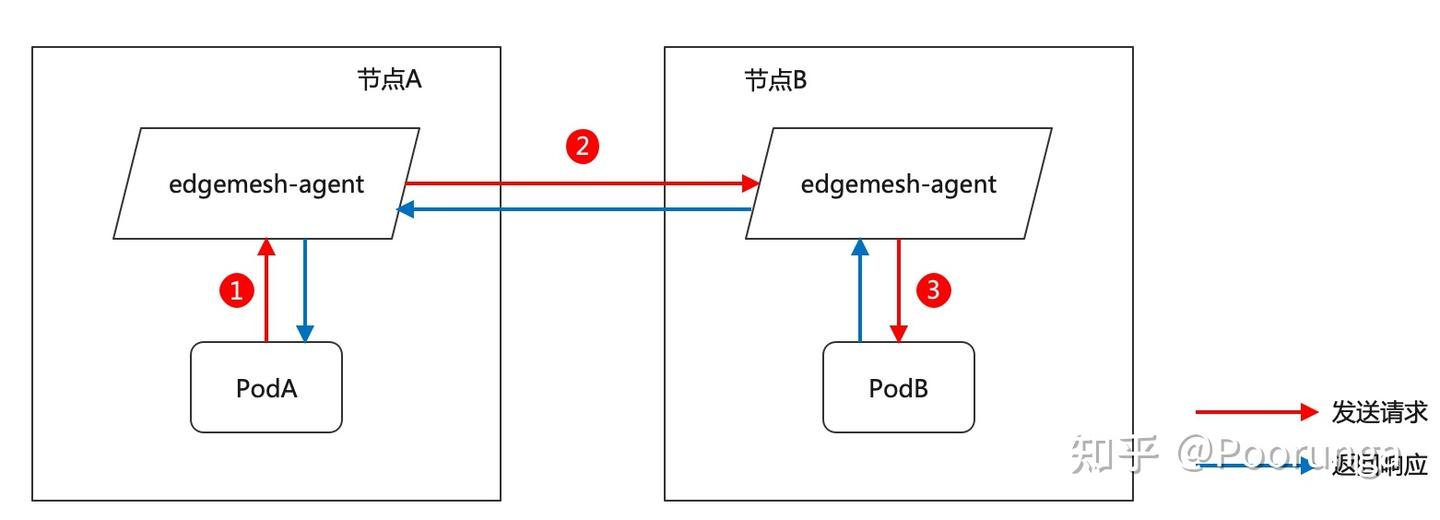
This situation is common since the master node usually has taints, which will evict other pods, thereby causing the deployment failure of edgemesh-agent. This issue can be resolved by removing the node taints.
If both the visiting node and the visited node's edgemesh-agent have been started normally while this error is still reported, it may be due to unsucessful discovering between the visiting node and the visited node. Please troubleshoot in this way:
- edgemesh-agent at each node has a peer ID (generated with the hash of node name):
edge1:
I'm {12D3KooWFz1dKY8L3JC8wAY6sJ5MswvPEGKysPCfcaGxFmeH7wkz: [/ip4/127.0.0.1/tcp/20006 /ip4/192.168.1.2/tcp/20006]}
edge2:
I'm {12D3KooWPpY4GqqNF3sLC397fMz5ZZfxmtMTNa1gLYFopWbHxZDt: [/ip4/127.0.0.1/tcp/20006 /ip4/192.168.1.4/tcp/20006]}
-
If visiting node and visited node are in the same LAN with internet IP, refer to Question 12 in EdgeMesh Q&A. Logs of discovering node in the same LAN is
[MDNS] Discovery found peer: <visited node peer ID: [visited IP list(include relay node IP)]>. -
If visiting node and visited node are across different LANs, check setting of relayNodes (Details at KubeEdge EdgeMesh Architecture). Logs of discovering node across LANs is
[DHT] Discovery found peer: <visited node peer ID: [visited IP list(include relay node IP)]>.
Solution:
Before deploy EdgeMesh with kubectl apply -f build/agent/resources/, modify file 04-configmap.yaml and add relayNode.
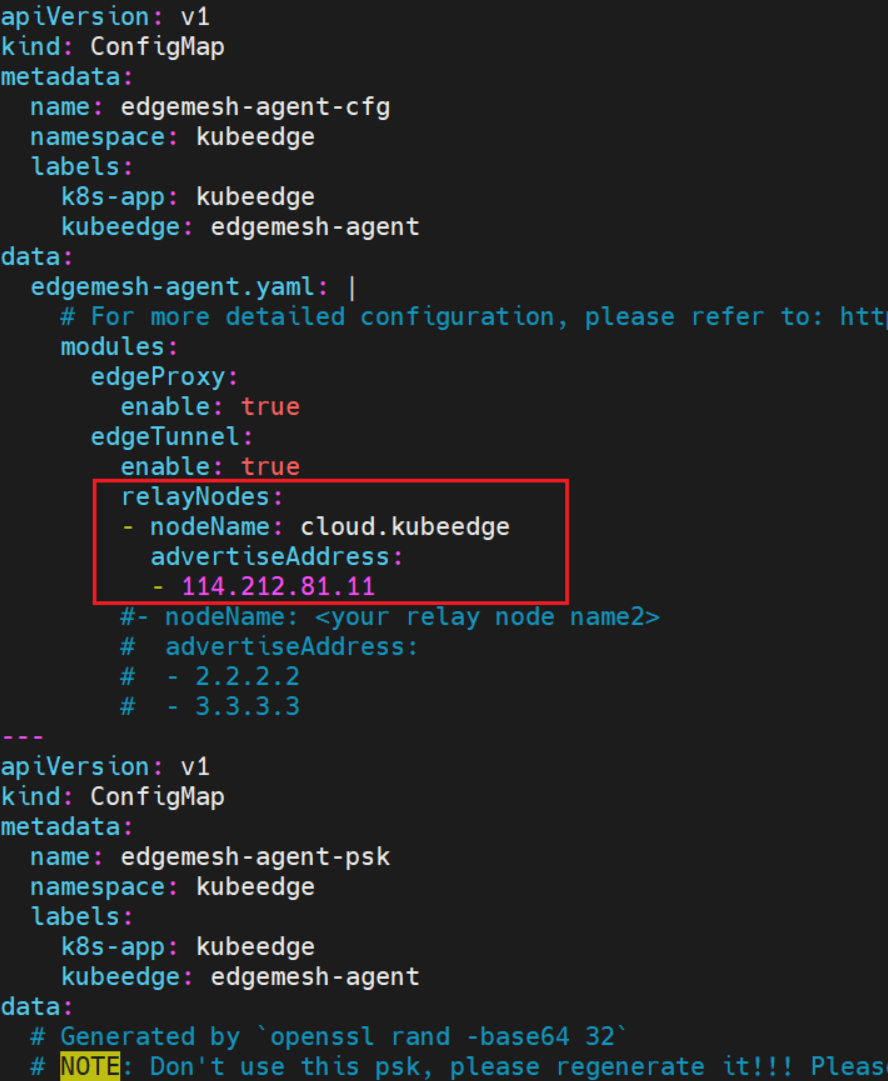
Question 8: GPU is not found on master
Use nvidia-smi to see GPU status on the cloud server. To support GPU in k8s pod on cloud server, extra plugin is needed.
Please refer to the following link: Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.14.3 documentation
Configure as the link, and add default-runtime in '/etc/docker/daemon.json' (remember to restart docker after modification):
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
Question 9: cannot find GPU resources in jetson
k8s-device-plugin has been installed successfully, but nvidia pod on jetson nodes (with tegra architecture) reveals that gpu is not found:
2024/01/04 07:43:58 Retreiving plugins.
2024/01/04 07:43:58 Detected non-NVML platform: could not load NVML: libnvidia-ml.so.1: cannot open shared object file: No such file or directory
2024/01/04 07:43:58 Detected non-Tegra platform: /sys/devices/soc0/family file not found
2024/01/04 07:43:58 Incompatible platform detected
2024/01/04 07:43:58 If this is a GPU node, did you configure the NVIDIA Container Toolkit?
2024/01/04 07:43:58 You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites
2024/01/04 07:43:58 You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start
2024/01/04 07:43:58 If this is not a GPU node, you should set up a toleration or nodeSelector to only deploy this plugin on GPU nodes
2024/01/04 07:43:58 No devices found. Waiting indefinitely.

dpkg -l '*nvidia*'
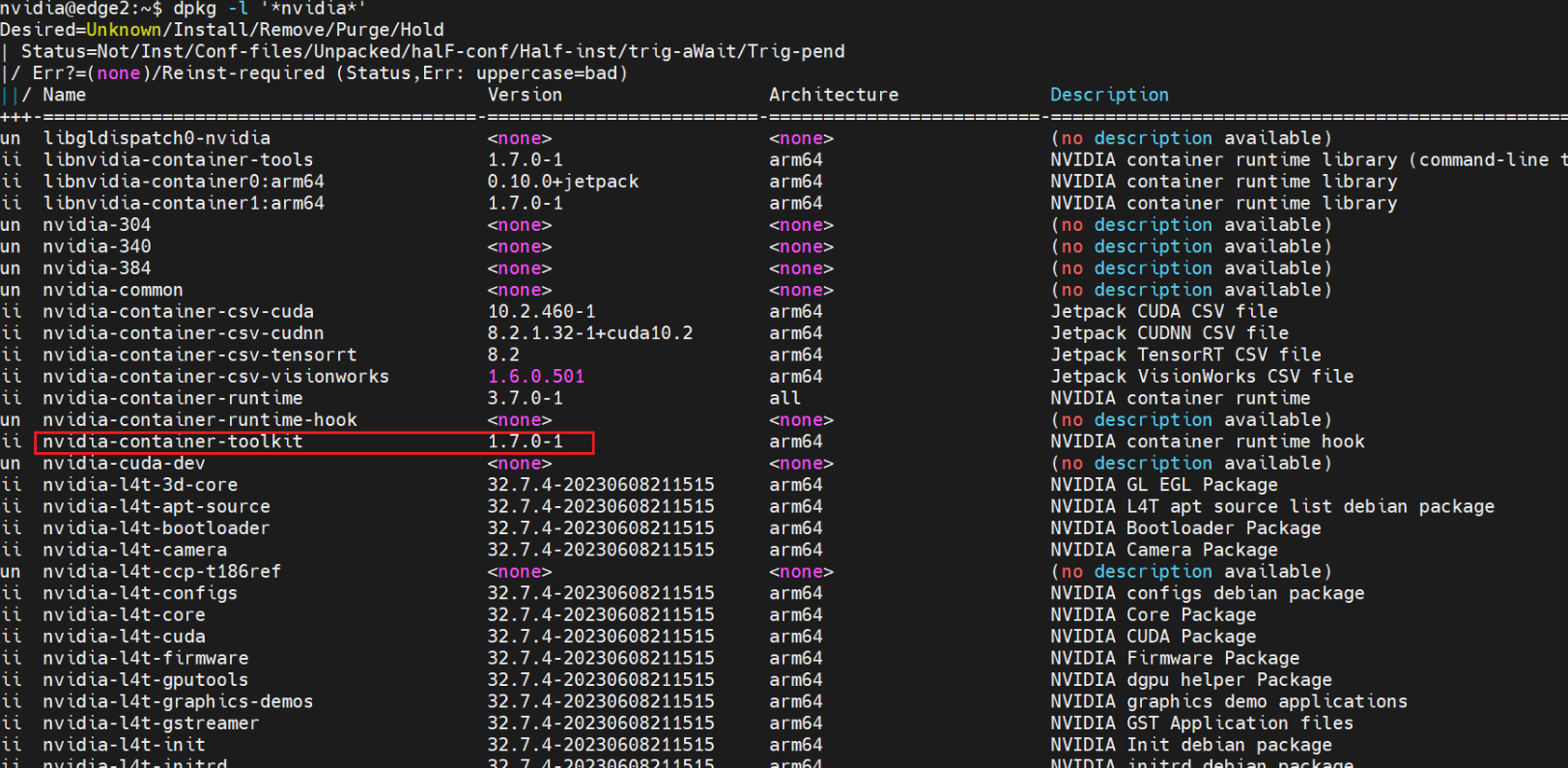
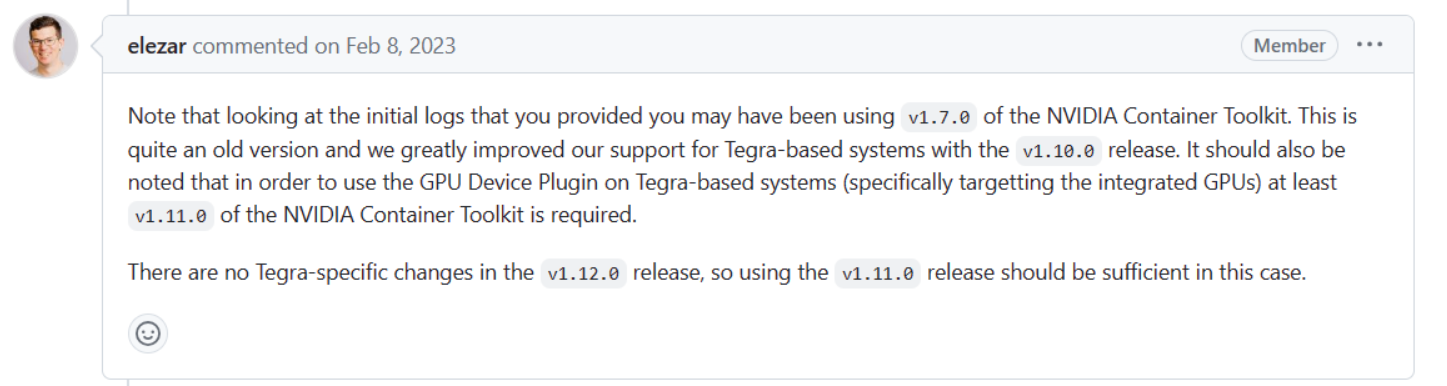
Plug in does not detect Tegra device Jetson Nano · Issue #377 · NVIDIA/k8s-device-plugin (github.com)Note that looking at the initial logs that you provided you may have been using
v1.7.0of the NVIDIA Container Toolkit. This is quite an old version and we greatly improved our support for Tegra-based systems with thev1.10.0release. It should also be noted that in order to use the GPU Device Plugin on Tegra-based systems (specifically targetting the integrated GPUs) at leastv1.11.0of the NVIDIA Container Toolkit is required.There are no Tegra-specific changes in thev1.12.0release, so using thev1.11.0release should be sufficient in this case.
Solution: Upgrade the NVIDIA Container Toolkit on jetson nodes.
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
Question 10: lc127.0.0. 53:53 no such host/connection refused
During the Sedna installation stage, an error occurs in logs: lc127.0.0. 53:53 no such host/connection refused.
Reason: See question 5 in EdgeMesh Q&A.
Solution:
First check whether Hostnetwork is in the script install.sh. Delete Hostnetwork options if it exists (install.sh in dayu-cusomized sedna is correct).
If Hostnetwork does not exist but the error is still reported, use the following method to temporarily solve (not recommend):
- Add
nameserver 169.254.96.16to the last line of file/etc/resolv.confon edge nodes with sedna pod error. - Check whether clusterDNS is
169.254.96.16in/etc/kubeedge/config/edgecore.yamlon edge nodes. - If error still exists, reinstall Sedna.
Question 11: 169.254.96.16:no such host
Check the configuration of EdgeMesh:
- Check the chain in iptables as Hybrid proxy | EdgeMesh.
- Check
clusterDNSas required in EdgeMesh Installation.
Question 12: kubectl logs <pod-name> timeout
![]()
Reason: Refer to Kubernetes nodes cannot capture monitoring metrics(zhihu.com)
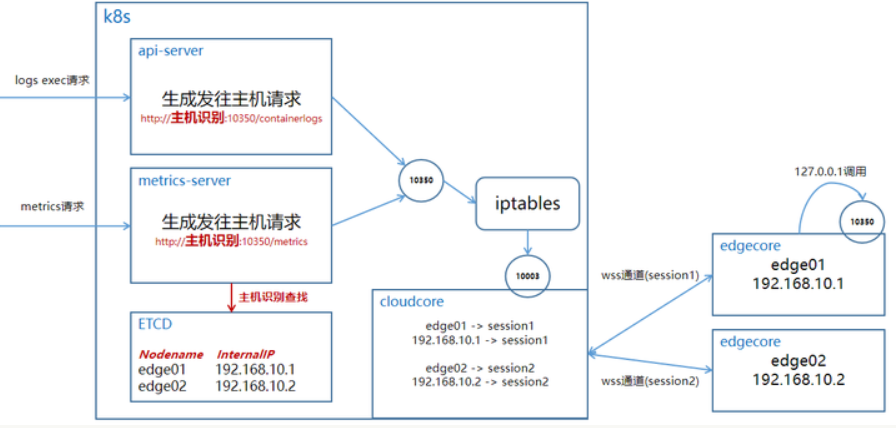
It can be found that the error happened in port 10350, which is responsible for forwarding in kubeedge.
Therefore, it should be a configuration issue with cloudcore.
Solution: Please set as Enable Kubectl logs/exec to debug pods on the edge | KubeEdge.
Question 13: Stuck in kubectl logs <pod-name>
Reason: It maybe caused by the force termination of kubectl logs command.
Solution: Restart edgecore/cloudcore:
# on cloud
systemctl restart cloudcore.service
# on edge
systemctl restart edgecore.service
Question 14: CloudCore reports certficate error

Reason: Token of master has changed.
Solution: Use new token from cloud to join.
Question 15: deleting namespace stucks in terminating state
Method 1 (Probably won't work)
kubectl delete ns sedna --force --grace-period=0
Method 2:
Open a proxy terminal:
kubectl proxy
Starting to serve on 127.0.0.1:8001
Open an operating terminal:
# save configuration file of namespace (use sedna as example here)
kubectl get ns sedna -o json > sedna.json
# Delete the contents of spec and status sections and the "," sign after the metadata field.
The remaining content in sedna.json is shown as follows:
Details
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"creationTimestamp": "2023-12-14T09:12:13Z",
"deletionTimestamp": "2023-12-14T09:15:25Z",
"managedFields": [
{
"apiVersion": "v1",
"fieldsType": "FieldsV1",
"fieldsV1": {
"f:status": {
"f:phase": {}
}
},
"manager": "kubectl-create",
"operation": "Update",
"time": "2023-12-14T09:12:13Z"
},
{
"apiVersion": "v1",
"fieldsType": "FieldsV1",
"fieldsV1": {
"f:status": {
"f:conditions": {
".": {},
"k:{\"type\":\"NamespaceContentRemaining\"}": {
".": {},
"f:lastTransitionTime": {},
"f:message": {},
"f:reason": {},
"f:status": {},
"f:type": {}
},
"k:{\"type\":\"NamespaceDeletionContentFailure\"}": {
".": {},
"f:lastTransitionTime": {},
"f:message": {},
"f:reason": {},
"f:status": {},
"f:type": {}
},
"k:{\"type\":\"NamespaceDeletionDiscoveryFailure\"}": {
".": {},
"f:lastTransitionTime": {},
"f:message": {},
"f:reason": {},
"f:status": {},
"f:type": {}
},
"k:{\"type\":\"NamespaceDeletionGroupVersionParsingFailure\"}": {
".": {},
"f:lastTransitionTime": {},
"f:message": {},
"f:reason": {},
"f:status": {},
"f:type": {}
},
"k:{\"type\":\"NamespaceFinalizersRemaining\"}": {
".": {},
"f:lastTransitionTime": {},
"f:message": {},
"f:reason": {},
"f:status": {},
"f:type": {}
}
}
}
},
"manager": "kube-controller-manager",
"operation": "Update",
"time": "2023-12-14T09:15:30Z"
}
],
"name": "sedna",
"resourceVersion": "3351515",
"uid": "99cb8afb-a4c1-45e6-960d-ff1b4894773d"
}
}
Delete namespace by call the interface:
curl -k -H "Content-Type: application/json" -X PUT --data-binary @sedna.json http://127.0.0.1:8001/api/v1/namespaces/sedna/finalize
curl -k -H "Content-Type: application/json" -X PUT --data-binary @sedna.json http://127.0.0.1:8001/api/v1/namespaces/sedna/finalize
{
"kind": "Namespace",
"apiVersion": "v1",
"metadata": {
"name": "sedna",
"uid": "99cb8afb-a4c1-45e6-960d-ff1b4894773d",
"resourceVersion": "3351515",
"creationTimestamp": "2023-12-14T09:12:13Z",
"deletionTimestamp": "2023-12-14T09:15:25Z",
"managedFields": [
{
"manager": "curl",
"operation": "Update",
"apiVersion": "v1",
"time": "2023-12-14T09:42:38Z",
"fieldsType": "FieldsV1",
"fieldsV1": {"f:status":{"f:phase":{}}}
}
]
},
"spec": {
},
"status": {
"phase": "Terminating",
"conditions": [
{
"type": "NamespaceDeletionDiscoveryFailure",
"status": "True",
"lastTransitionTime": "2023-12-14T09:15:30Z",
"reason": "DiscoveryFailed",
"message": "Discovery failed for some groups, 1 failing: unable to retrieve the complete list of server APIs: metrics.k8s.io/v1beta1: the server is currently unable to handle the request"
},
{
"type": "NamespaceDeletionGroupVersionParsingFailure",
"status": "False",
"lastTransitionTime": "2023-12-14T09:15:30Z",
"reason": "ParsedGroupVersions",
"message": "All legacy kube types successfully parsed"
},
{
"type": "NamespaceDeletionContentFailure",
"status": "False",
"lastTransitionTime": "2023-12-14T09:15:30Z",
"reason": "ContentDeleted",
"message": "All content successfully deleted, may be waiting on finalization"
},
{
"type": "NamespaceContentRemaining",
"status": "False",
"lastTransitionTime": "2023-12-14T09:15:30Z",
"reason": "ContentRemoved",
"message": "All content successfully removed"
},
{
"type": "NamespaceFinalizersRemaining",
"status": "False",
"lastTransitionTime": "2023-12-14T09:15:30Z",
"reason": "ContentHasNoFinalizers",
"message": "All content-preserving finalizers finished"
}
]
}
}
Question 16: Deployment failed after forcibly deleting pod
Deployment creates pods. But after deleting deployment through kubectl delete deploy <deploy-name>, pods are stuck in 'terminating' status.
Then, use kubectl delete pod edgeworker-deployment-7g5hs-58dffc5cd7-b77wz --force --grace-period=0 to delete pods. And the re-deployed pods are stuck in 'pending' state after assigning to node.
Solution:
Deleting pods with option --force does not actually terminate pods.
You should go to the specific node and manually delete the corresponding docker containers (including pause, see details at Pause in K8S Pod)
# Check pod position on cloud
kubectl get pods -A -owide
# Delete docker containers on specific node (the position of pod)
docker ps -A
docker stop <container>
docker rm <container>
# Restart edgecore on specific node (the pod)
systemctl restart edgecore.service
Question 17: After deleting deployments and pods, the pods still restart automatically
journalctl -u edgecore.service -f

Solution: Restart edgecore:
systemctl restart edgecore.service
Question 18: Large-scale Evicted (disk pressure)
Reason:
The free disk space (usually root directory) is below the threshold (15%), and kubelet will kill pods to recycle resources (Details at K8S Insufficient Resource).
Solution:
The fundamental solution is to increase the available disk space.
If a temporary solution is needed, the threshold can be changed by modifying the k8s configuration.
Specifically, modify the configuration file and add --eviction-hard=nodefs.available<5%:
systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Fri 2023-12-15 09:17:50 CST; 5min ago
Docs: https://kubernetes.io/docs/home/
Main PID: 1070209 (kubelet)
Tasks: 59 (limit: 309024)
Memory: 67.2M
CGroup: /system.slice/kubelet.service
From the outputs you can see that configuration file is at directory /etc/systemd/system/kubelet.service.d
and configuration file is 10-kubeadm.conf.
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml --eviction-hard=nodefs.available<5%"
# add '--eviction-hard=nodefs.available<5%' at the end
Restart kubelet:
systemctl daemon-reload
systemctl restart kubelet
You will find that it can be deployed normally (it's just a temporary method, the disk space needs to be cleaned up).
Question 19: Executing 'iptables' report that system does not support '--dport'
When executing command iptables -t nat -A OUTPUT -p tcp --dport 10351 -j DNAT --to $CLOUDCOREIPS:10003, an error of not supporting --dport is reported.
Reason: The iptables version not support --dport:
# Check iptables version
iptables -V
# Version of 'iptables v1.8.7 (nf_tables)' does not support '--dport'
Solution:
# Switch version. In the three options, choose 'legacy'
sudo update-alternatives --config iptables
# verify (success with no error)
iptables -t nat -A OUTPUT -p tcp --dport 10351 -j DNAT --to $CLOUDCOREIPS:10003
Question 20: Report 'token format error' after 'keadm join'
After executing command keadm join --cloudcore-ipport=114.212.81.11:10000 --kubeedge-version=1.9.2 --token=……, journalctl -u edegecore.service -freport error of token format.
Solution:
Token is error or expired when joining. Therefore, get the latest token from cloud and redo from keadm reset.
Question 21: Report mapping errors after restart edgecore.service
After executing command systemctl restart edgecore.service to restart edgecore, journalctl -u edegecore.service -f report mapping error of failing to translate yaml to json.
Solution:
Check the format in file/etc/kubeedge/config/edgecore.yaml. Note that tab is not allowed in YAML files (use space instead).
Question 22: Restart edgecore and find error of 'connect refuse'
During the startup of EdgeMesh, modify the /etc/kubeedge/config/edgecore.yaml file and restart the service with systemctl restart edgecore.service.
Command journalctl -u edegecore.service -f report an error of 'connect refuse' and the cloud denies communication.
Solution:
Check the status of cloudcore on cloud:
# check cloudcore status
systemctl status cloudcore
# restart cloudcore
systemctl restart cloudcore.service
# check error message
journalctl -u cloudcore.service -f
An error of Question 4 maybe found.
Question 23: Error of 'Shutting down' is reported when deploying metrics-service
During the deployment of metrics-service, the port in the components.yaml file is modified to '4443', but metrics-service still failed with error Shutting down RequestHeaderAuthRequestController occurred.
Solution:
When deploying KubeEdge, the port in the metrics-service will be automatically overwritten to '10250'. Manually modify the port in components.yaml file to '10250'.
Question 24: 169.254.96. 16:53: i/o timeout
When a new node joins in the cluster, Sedna will be deployed automatically.
An error is reported in the log of sedna-lc:
client tries to connect global manager(address: gm.sedna:9000) failed, error: dial tcp: lookup gm.sedna on 169.254.96.16:53: read udp 172.17.0.3:49991->169.254.96.16:53: i/o timeout
Troubleshooting:
First check status of edgemesh-agent on the new node. The error is reported from edgemesh-agent:

Use kubectl describe pod <pod-name> and find that assigning to new node is the latest event:
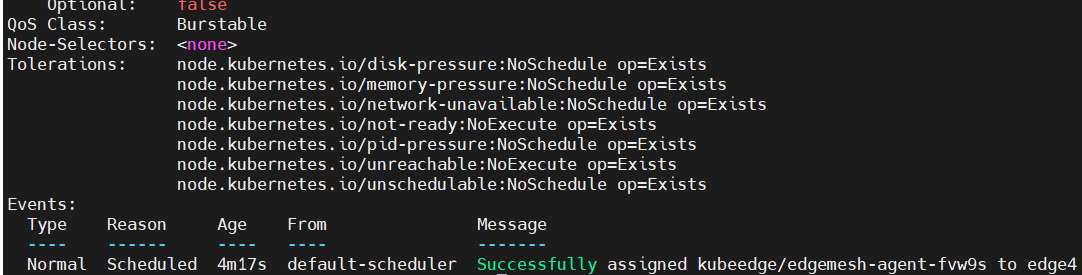
Use journalctl -u edgecore.service -xe on the new node to check errors:

Reason: The new node cannot access dockerhub directly and has not been configured of docker registry. Thus, docker image cannot be pulled.
Solution: Configure docker registry and restart docker and edgecore. Refer to Docker Registry Configuration for details.
Question 25: keadm join error on edge nodes
Execution of keadm join on edges reported errors.
Solution: Check the edgecore.yaml file:
vim /etc/kubeedge/config/edgecore.yaml
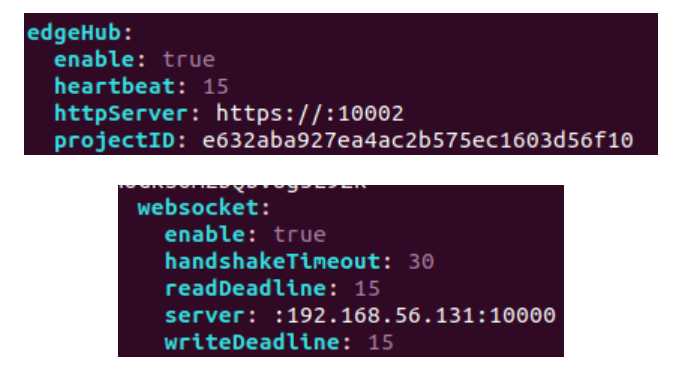
Add the address of master node (cloud) in edgeHub/httpServer, such as https://114.212.81.11:10002,
delete the redundant ':' in websocket/server.
Re-run the keadm join command after modification.
Question 26: Failed to build map of initial containers from runtime
Edgecore report error when journalctl -u edgecore.service -f:
initialize module error: failed to build map of initial containers from runtime: no PodsandBox found with Id 'c45ed1592e75e885e119664d777107645a7e7904703c690664691c61a9f79ed3'
Solution:
Find the docker ID and delete it:
docker ps -a --filter "label=io.kubernetes.sandbox.id=c45ed1592e75e885e119664d777107645a7e7904703c690664691c61a9f79ed3"
# find the related docker ID
docker rm <docker ID>
Question 27: Certificate has expired or is not yet valid
Execution of kubectl get pods -A reports the following error:
Unable to connect to the server: x509: certificate has expired or is not yet valid: current time 2025-06-27T22:23:12+08:00 is after 2025-06-27T08:56:50Z
Reason:
Check the certificate of Kubernetes on the cloud server:
sudo kubeadm certs check-expiration
# Get the following results
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[check-expiration] Error reading configuration from the Cluster. Falling back to default configuration
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Jun 27, 2025 08:56 UTC <invalid> no
apiserver Jun 27, 2025 08:56 UTC <invalid> ca no
apiserver-etcd-client Jun 27, 2025 08:56 UTC <invalid> etcd-ca no
apiserver-kubelet-client Jun 27, 2025 08:56 UTC <invalid> ca no
controller-manager.conf Jun 27, 2025 08:56 UTC <invalid> no
etcd-healthcheck-client Jun 27, 2025 08:56 UTC <invalid> etcd-ca no
etcd-peer Jun 27, 2025 08:56 UTC <invalid> etcd-ca no
etcd-server Jun 27, 2025 08:56 UTC <invalid> etcd-ca no
front-proxy-client Jun 27, 2025 08:56 UTC <invalid> front-proxy-ca no
scheduler.conf Jun 27, 2025 08:56 UTC <invalid> no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Jun 25, 2034 08:56 UTC 8y no
etcd-ca Jun 25, 2034 08:56 UTC 8y no
front-proxy-ca Jun 25, 2034 08:56 UTC 8y no
The certificates are in status of <invalid>.
Solution:
Update Kubernetes certificates:
sudo kubeadm certs renew all
# Get the following results:
[renew] Reading configuration from the cluster...
[renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[renew] Error reading configuration from the Cluster. Falling back to default configuration
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed
certificate for serving the Kubernetes API renewed
certificate the apiserver uses to access etcd renewed
certificate for the API server to connect to kubelet renewed
certificate embedded in the kubeconfig file for the controller manager to use renewed
certificate for liveness probes to healthcheck etcd renewed
certificate for etcd nodes to communicate with each other renewed
certificate for serving etcd renewed
certificate for the front proxy client renewed
certificate embedded in the kubeconfig file for the scheduler manager to use renewed
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.
Recheck the certificates, all certificates are updated:
sudo kubeadm certs check-expiration
# Get the following results:
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[check-expiration] Error reading configuration from the Cluster. Falling back to default configuration
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Jun 27, 2026 14:30 UTC 364d no
apiserver Jun 27, 2026 14:30 UTC 364d ca no
apiserver-etcd-client Jun 27, 2026 14:30 UTC 364d etcd-ca no
apiserver-kubelet-client Jun 27, 2026 14:30 UTC 364d ca no
controller-manager.conf Jun 27, 2026 14:30 UTC 364d no
etcd-healthcheck-client Jun 27, 2026 14:30 UTC 364d etcd-ca no
etcd-peer Jun 27, 2026 14:30 UTC 364d etcd-ca no
etcd-server Jun 27, 2026 14:30 UTC 364d etcd-ca no
front-proxy-client Jun 27, 2026 14:30 UTC 364d front-proxy-ca no
scheduler.conf Jun 27, 2026 14:30 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Jun 25, 2034 08:56 UTC 8y no
etcd-ca Jun 25, 2034 08:56 UTC 8y no
front-proxy-ca Jun 25, 2034 08:56 UTC 8y no
However, the execution of command kubectl get pods -A still reports errors:
error: You must be logged in to the server (Unauthorized)
Renew the configuration file and restart core k8s services to solve:
# Backup configuration file
cp -rp $HOME/.kube/config $HOME/.kube/config.bak
# Renew configuration file
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo cp -i /etc/kubernetes/admin.conf /root/.kube/config
# Restart kubelet
sudo systemctl restart kubelet
# Restart kube-apiserver, kube-controller-manage, kube-scheduler
docker ps |grep kube-apiserver|grep -v pause|awk '{print $1}'|xargs -i docker restart {}
docker ps |grep kube-controller-manage|grep -v pause|awk '{print $1}'|xargs -i docker restart {}
docker ps |grep kube-scheduler|grep -v pause|awk '{print $1}'|xargs -i docker restart {}
Restart Cloudcore and check the status:
# Restart Cloudcore
sudo systemctl restart cloudcore
# Check Cloudcore status
systemctl status cloudcore
journalctl -u cloudcore -xe
If Cloudcore has the following errors:
cloudcore.service: Main process exited, code=exited, status=2/INVALIDARGUMENT
cloudcore.service: Main process exited, code=exited, status=2/INVALIDARGUMENT
-- A start job for unit cloudcore.service has finished successfully.
--
-- The job identifier is 2357999.
6月 30 00:45:15 cloud.kubeedge cloudcore[3159196]: W0630 00:45:15.125171 3159196 validation.go:154]
TLSTunnelPrivateKeyFile does not exist i>
6月 30 00:45:15 cloud.kubeedge cloudcore[3159196]: W0630 00:45:15.125269 3159196 validation.go:157]
TLSTunnelCertFile does not exist in /etc>
6月 30 00:45:15 cloud.kubeedge cloudcore[3159196]: W0630 00:45:15.125286 3159196 validation.go:160] TLSTunnelCAFile
does not exist in /etc/k>
6月 30 00:45:15 cloud.kubeedge cloudcore[3159196]: I0630 00:45:15.125336 3159196 server.go:77] Version: v1.9.2
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: panic: failed to create system namespace
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: goroutine 1 [running]:
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]:
github.com/kubeedge/kubeedge/cloud/cmd/cloudcore/app.NewCloudCoreCommand.func1(0xc00035f8>
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: /root/kubeedge/cloud/cmd/cloudcore/app/server.go:85 +0x81c
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: github.com/spf13/cobra.(*Command).execute(0xc00035f8c0,
0xc00003c1f0, 0x0, 0x0, 0xc00035f>
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: /root/kubeedge/vendor/github.com/spf13/cobra/command.go:854
+0x2c2
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: github.com/spf13/cobra.(*Command).ExecuteC(0xc00035f8c0,
0xc000180058, 0x1859280, 0x0)
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: /root/kubeedge/vendor/github.com/spf13/cobra/command.go:958
+0x375
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: github.com/spf13/cobra.(*Command).Execute(...)
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: /root/kubeedge/vendor/github.com/spf13/cobra/command.go:895
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: main.main()
6月 30 00:45:16 cloud.kubeedge cloudcore[3159196]: /root/kubeedge/cloud/cmd/cloudcore/cloudcore.go:16 +0x65
6月 30 00:45:16 cloud.kubeedge systemd[1]: cloudcore.service: Main process exited, code=exited,
status=2/INVALIDARGUMENT
-- Subject: Unit process exited
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- An ExecStart= process belonging to unit cloudcore.service has exited.
--
-- The process' exit code is 'exited' and its exit status is 2.
6月 30 00:45:16 cloud.kubeedge systemd[1]: cloudcore.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- The unit cloudcore.service has entered the 'failed' state with result 'exit-code'.
Try to update Cloudcore certs:
# Modify the ip address of '--adverse-address'
keadm init --advertise-address=114.212.81.11 --kubeedge-version=1.9.2
# Check Cloudcore status
journalctl -u cloudcore -xe
# if Cloudcore journal report port connection refused, kill the occupied process
sudo lsof -i:<port>
sudo kill -9 <pid>
Remember to modify cloudcore.yaml as [Install KubeEdge] shows after keadm init.
Question 28: Connection refused in dayu containers
In dayu system containers, connection refused error is reported when accessing services, but the pods are normal and logs show no error.
Reason:
Check the status of edgemesh-agent on edge nodes:
kubectl get pods -n kubeedge -owide
kubectl logs -n kubeedge edgemesh-agent-xxxxx # xxxxx is the pod name
From the edgemesh-agent logs, we can see that service port conflict happens, then check iptables on edge nodes:
sudo iptables -t nat -nvL
Redundant iptable rules are recorded in KUBE-NODEPORT-CONTAINER, KUBE-NODEPORT-HOST, KUBE-PORTALS-CONTAINER and KUBE-PORTALS-HOST (which are residual after stop system).
Solution:
Temporarily, flush edgecore database on edge node (it may cause data loss):
# Stop edgecore
sudo systemctl stop edgecore
# Backup kubeedge data
sudo tar -czf /tmp/kubeedge-backup-$(date +%F-%H%M%S).tgz /var/lib/kubeedge
# Flush kubeedge data
sudo rm -rf /var/lib/kubeedge
sudo mkdir -p /var/lib/kubeedge
sudo chown -R root:root /var/lib/kubeedge
# Start edgecore
sudo systemctl start edgecore
# Check edgecore status
sudo journalctl -u edgecore -f --no-pager
Another temporary solution is to reinstall kubeedge on edge node as instruction shows.
Permanently, this error has been fixed after dayu v1.3 release. Use the latest dayu script can avoid this error.