Collaboration Scheduling Layer
The collaborative scheduling layer is the main structure for implementing the core functions of the dayu system, composed of multiple functional components independently developed by us. It provides full-process fine-grained operations such as processing, scheduling, and monitoring for stream data processing applications, thereby supporting real-time stream data analysis pipelines.
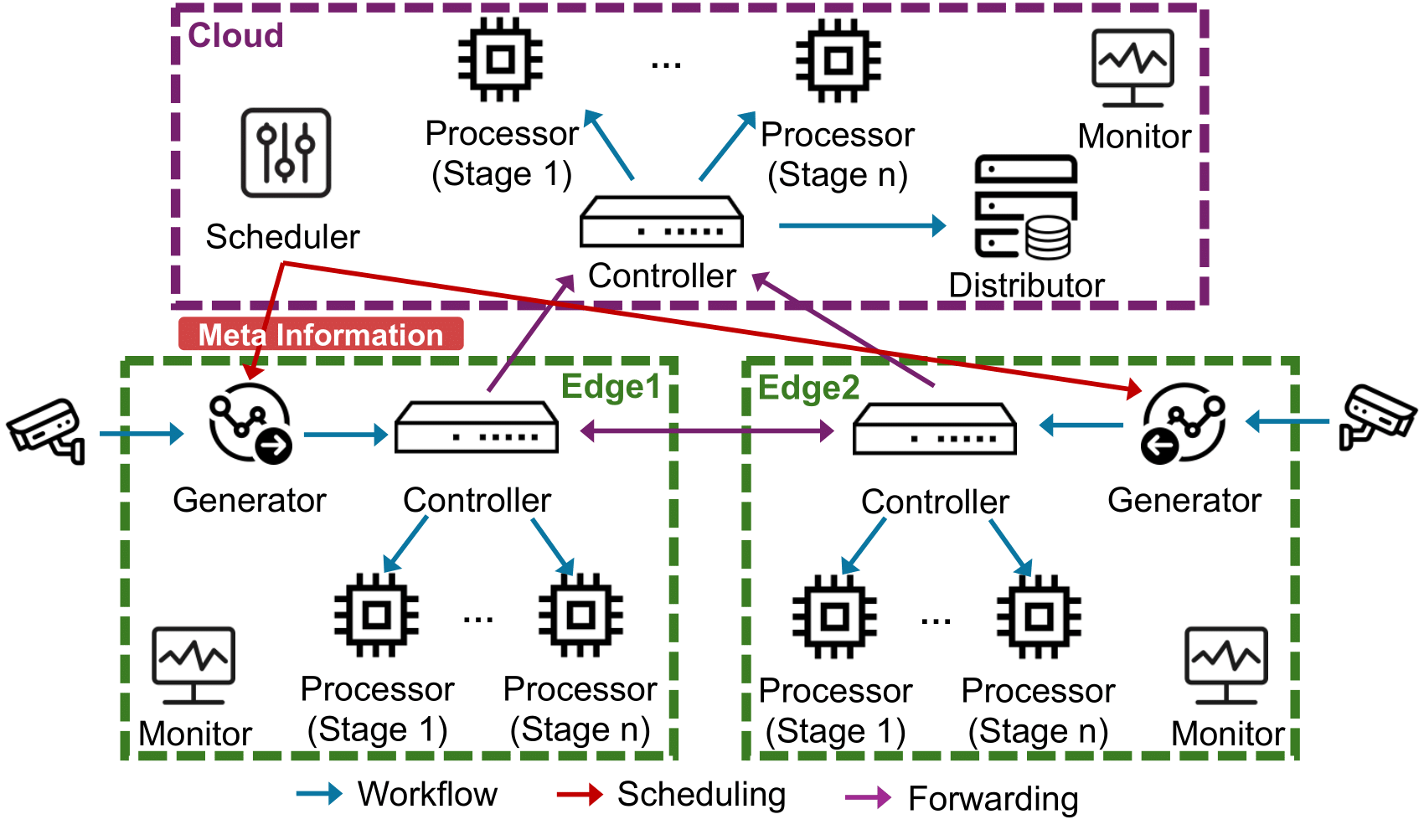
Specifically, the collaborative scheduling layer is mainly composed of six functional components: Generator, Controller, Processor, Distributor, Scheduler, and Monitor.
-
Generator is responsible for real-time capture of stream data and generating stream data processing tasks. A generator is deployed on each edge node, and each generator can be bound to a stream data source. After capturing the stream data of the data source, it performs operations such as splitting, preprocessing, etc. based on the configuration decisions given by the scheduler, forms stream data processing tasks, and sends the pending tasks to the corresponding node controllers for further analysis and processing according to the offloading decisions.
-
Controller is responsible for controlling the whole forwarding workflow of stream data processing tasks on cloud-edge distributed devices. A controller is deployed on each device in the cloud-edge distributed cluster, and the stream data processing tasks are forwarded between devices (enter the controller first). The controller completes specific forwarding based on the current status of the task, and the forwarding logic specifically includes completing AI algorithm processing at the corresponding stage processor of the current device, forwarding to other devices for further processing, and forwarding to the distributor to store completed task data, etc.
-
Processor is responsible for completing specific AI algorithm processing for stream data tasks. In the application service layer, a stream data processing application may contain one or more processing stages, each corresponding to a specific AI application service. Therefore, each processor encapsulates and embeds the specific logic of an AI application service and exposes a unified interface, thereby facilitating the completion of stream data processing service calls. All stages of processors are deployed on each device, thereby facilitating the offloading of tasks from any stage to any node for execution.
-
Distributor is responsible for collecting the processed data of completed stream data tasks. It only exists on the cloud server, collecting various data including specific processing results, process processing delay, scheduling decision information, etc., and completes the storage and distribution of data as required, such as distributing processing results to frontend and backend servers for display to users, and distributing processing information to the scheduler as scheduling feedback to adjust scheduling decisions.
-
Scheduler is responsible for generating scheduling decision information for stream data processing, including configuration decisions and offloading decisions, and it only exists on the cloud server. Specifically, configuration decisions refer to the preprocessing of stream data itself, such as downsampling; offloading decisions refer to the decision of offloading devices for each stage of stream data processing tasks. Based on the decision information generated by the scheduler, the dayu system can perform fine-grained scheduling switching control for stream data processing tasks.
-
Monitor is responsible for monitoring resource usage. Monitors exist on each device in the cloud-edge distributed cluster, monitoring internal resource status of the device, such as CPU usage rate, memory usage rate, etc.; also monitoring resource status between devices, such as network bandwidth between nodes.
Among these components, Generators, Controllers, Distributors, Schedulers, and Monitors are embedded in the platform and provide fine-grained pipeline task organization and scheduling, which are transparent and invisible to users. Processors can encapsulate single-stage or multi-stage (pipeline) application services defined by users in the application service layer, where each processor encapsulates an application service of a stage, and one or more processors can constitute a complete application processing flow.